About
Basic Model
Download
Docs
Literature
Home
Contact
Graciously hosted by
libnn - Basic Model
Neuron j itself sends information to its forward connected neurons k depending on the value of the received information and on a so called activation function; in short:
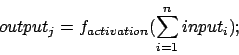
Mathematically a neuronal network could be described as a multidimensional graph, processing a given input to a certain output. The input is a vector of single inputvalues given as information to neurons defined as inputneurons, the output a vector of the feedforwarded information of so called endneurons. But where are the variables making this graph multidimensional?
In fact, the connections between the neurons do not only transmit the information but also change it: they can reinforce or inhibit it. Mathematically spoken, the information is multiplied by a certain factor, a so called weight or synapse. And these weights are the varibales. Thus the received information of neuron j is the sum of weigthed outputs of neurons i:
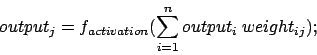
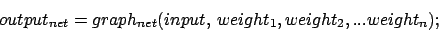
Indeed, the most interesting part (and also filling most lines of the code of libnn) is the training of a given network. This is, the way you try to adapt the weights so that the network recognizes correctly a given set of patterns.
There are three general trainings methods:
- The net is told by an extern teacher the correct output it shall produce to a certain pattern. By calculating the difference between the correct and real output the net can adapt its weights: supervised learning
- The net does not know the correct output. After changing its weights, it is told by a teacher if the output has become better or worse: reinforcement learning
- The network adapts it weights without knowing the right output and without the the help of any teacher: non supervised learning
- Backpropagation (Standard, Weight Decay, Momentum Term)
- Backpercolation
- Jordan Nets
- Elman Nets
- Real-Time Recurrent Learning
- RBF-Nets
- SOM